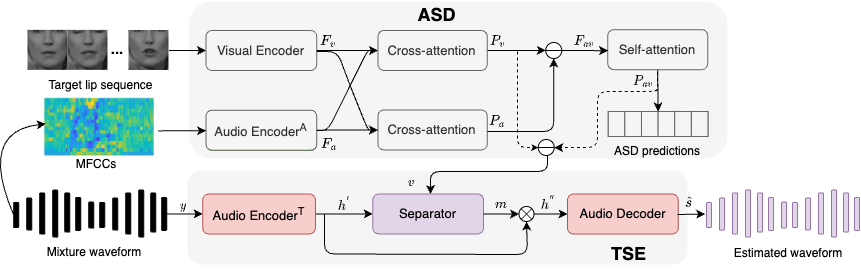
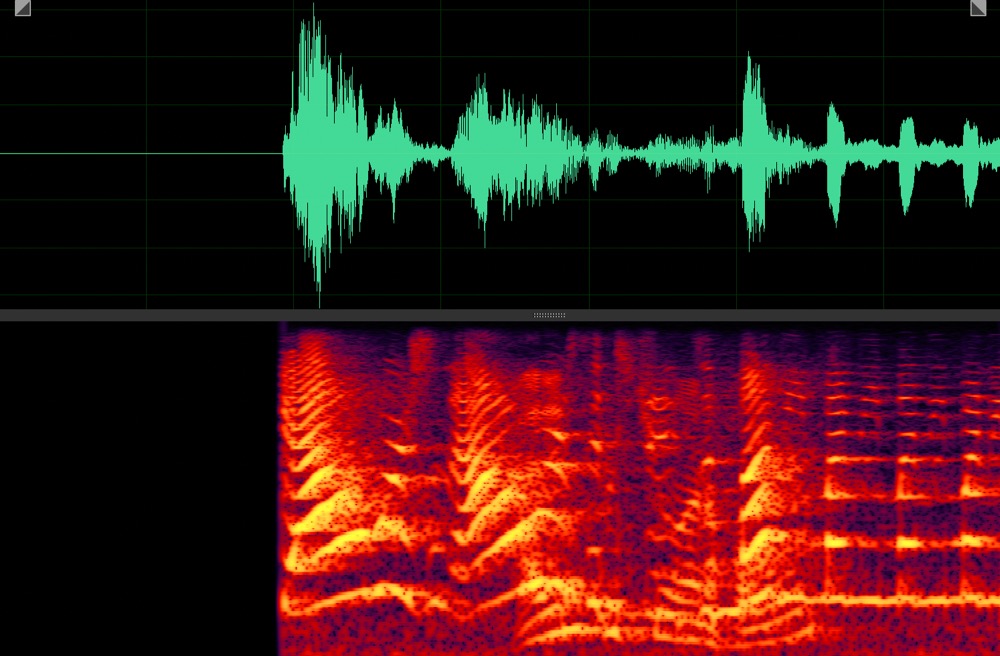
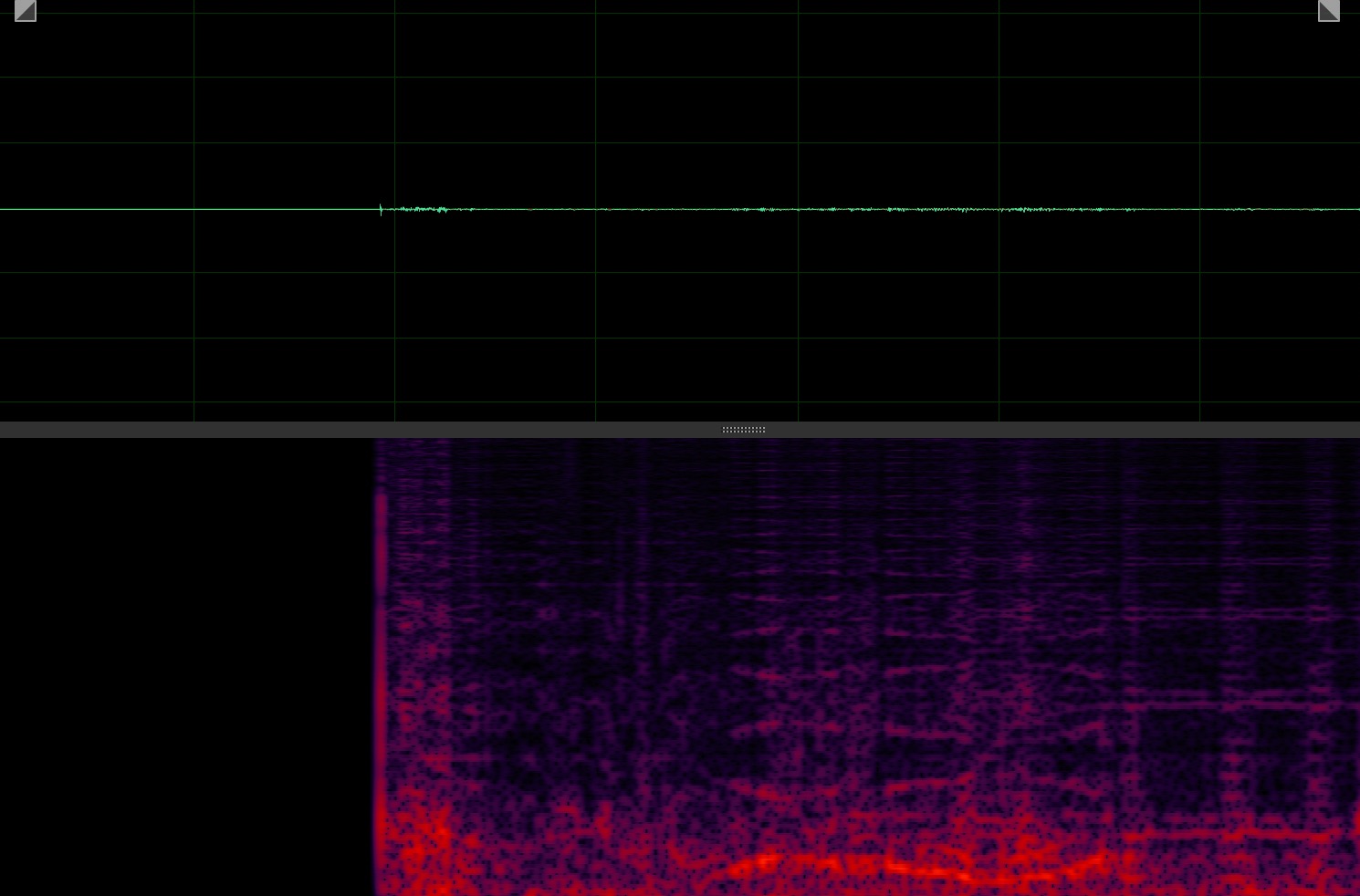
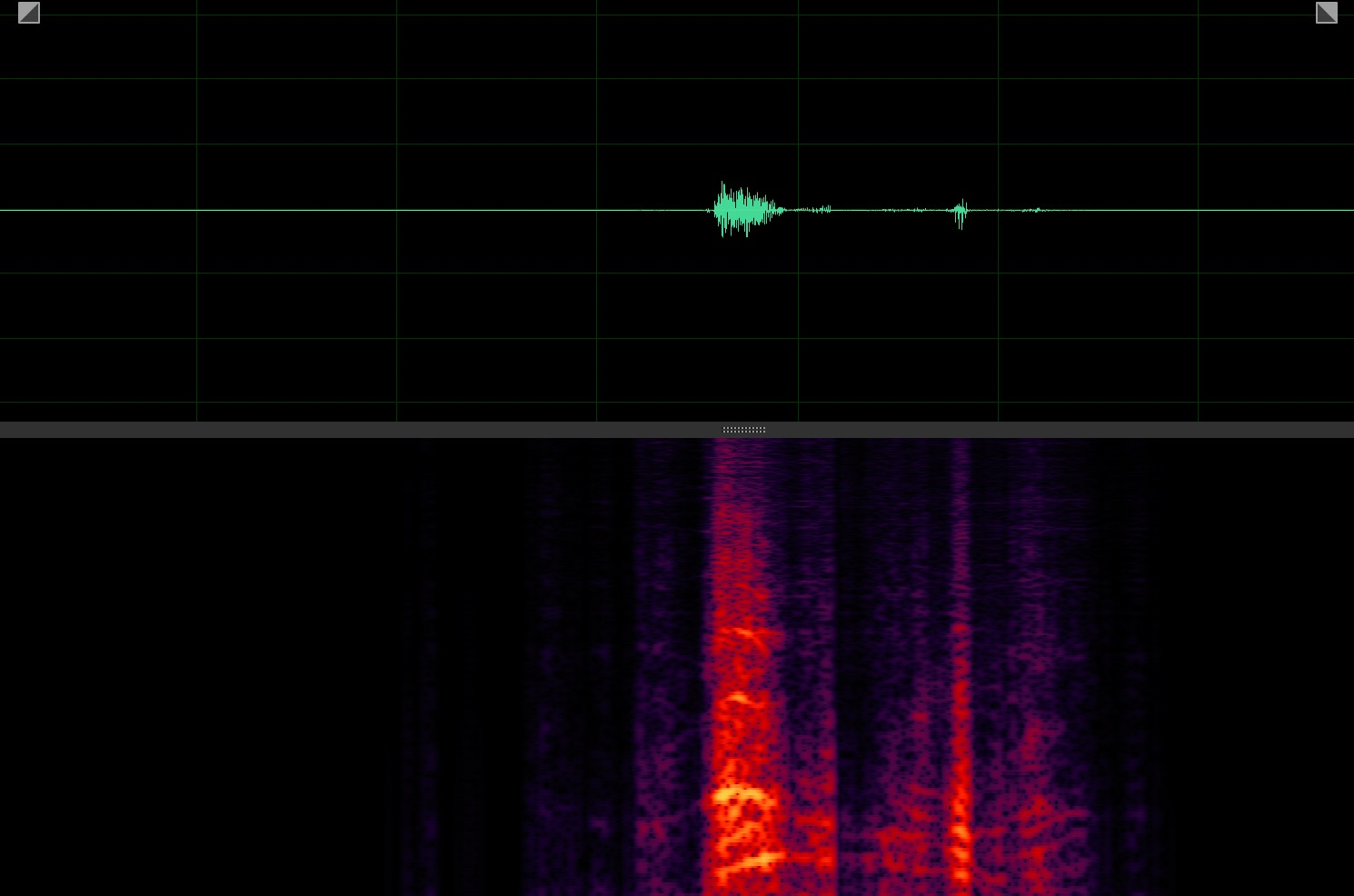
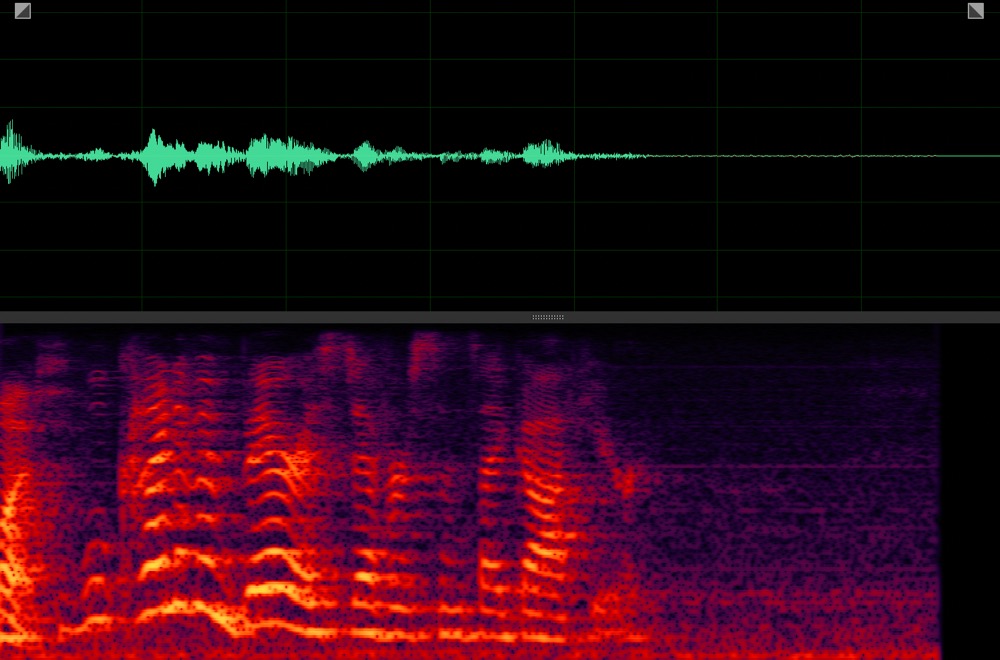
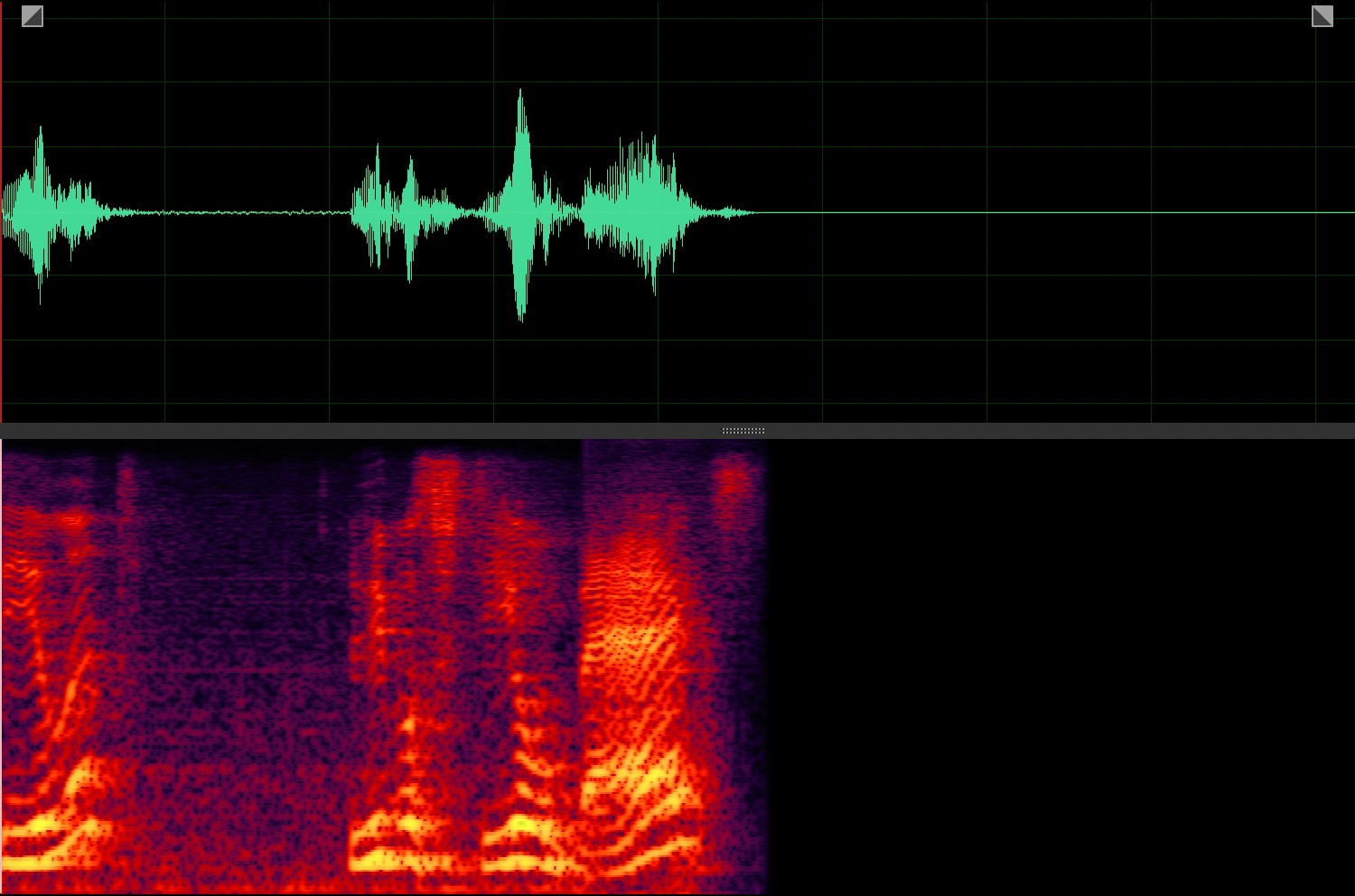
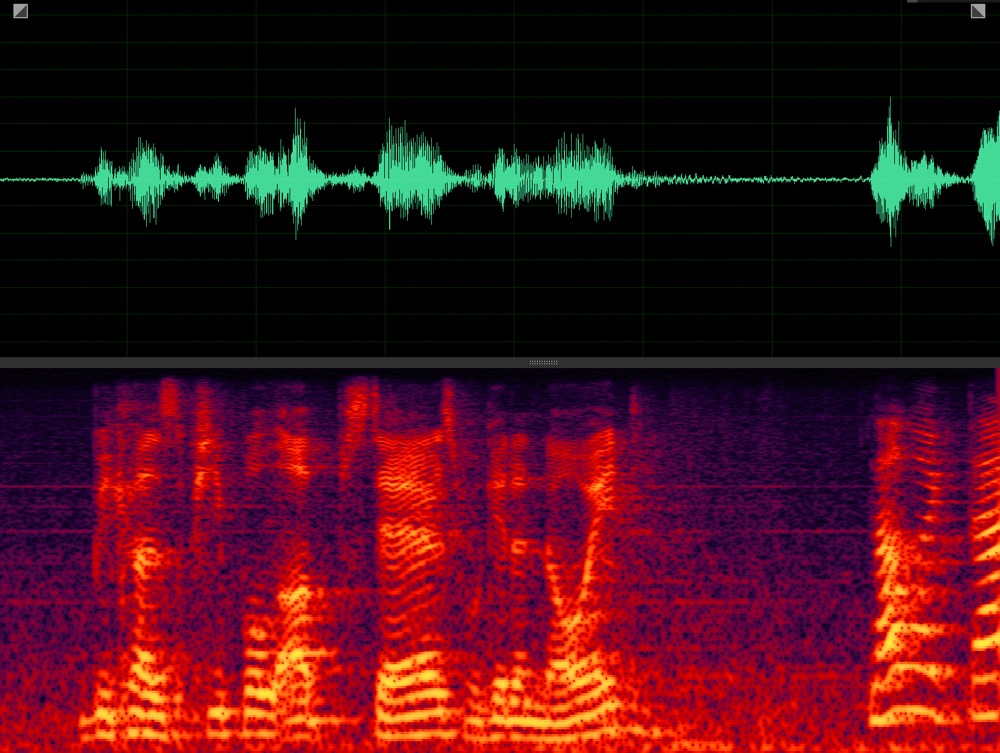
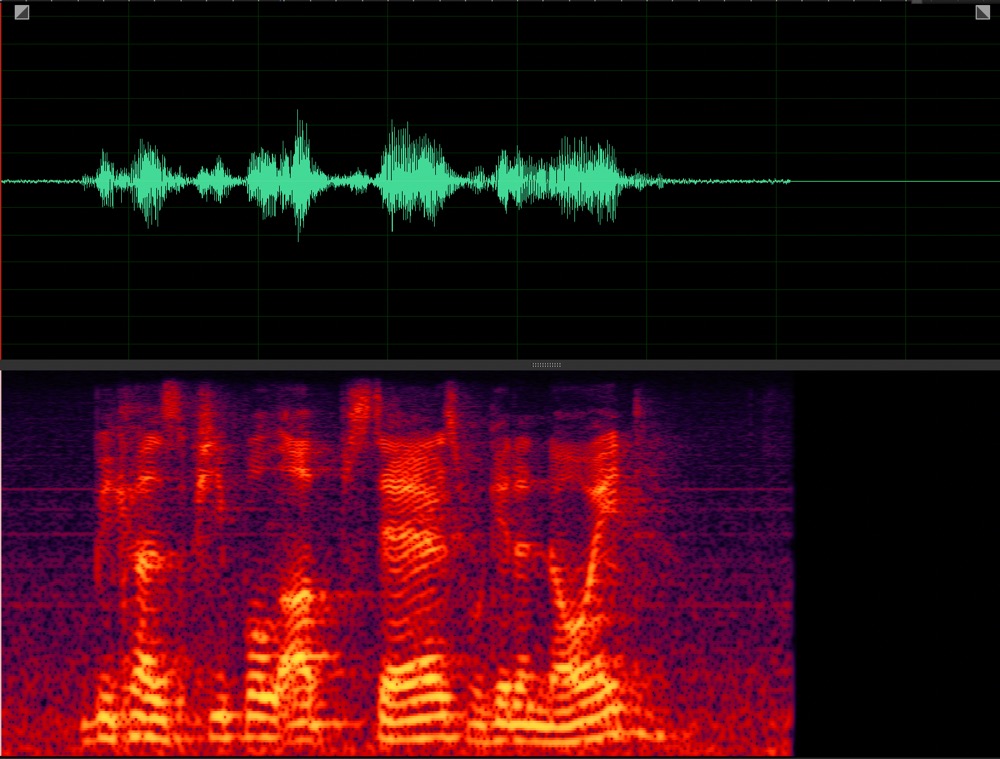
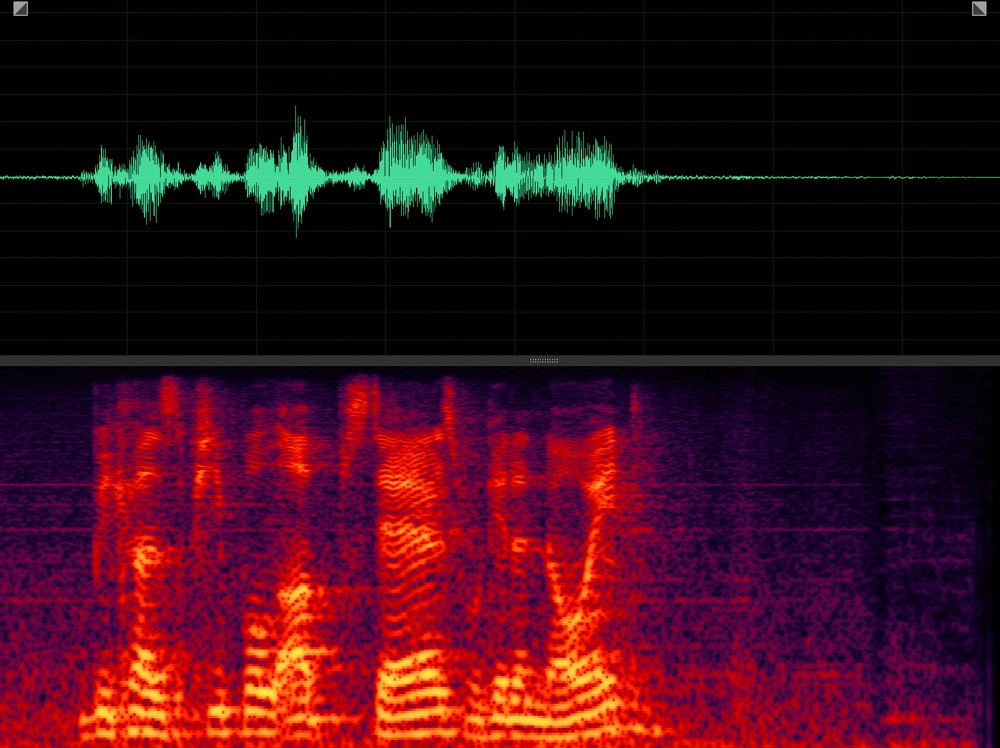
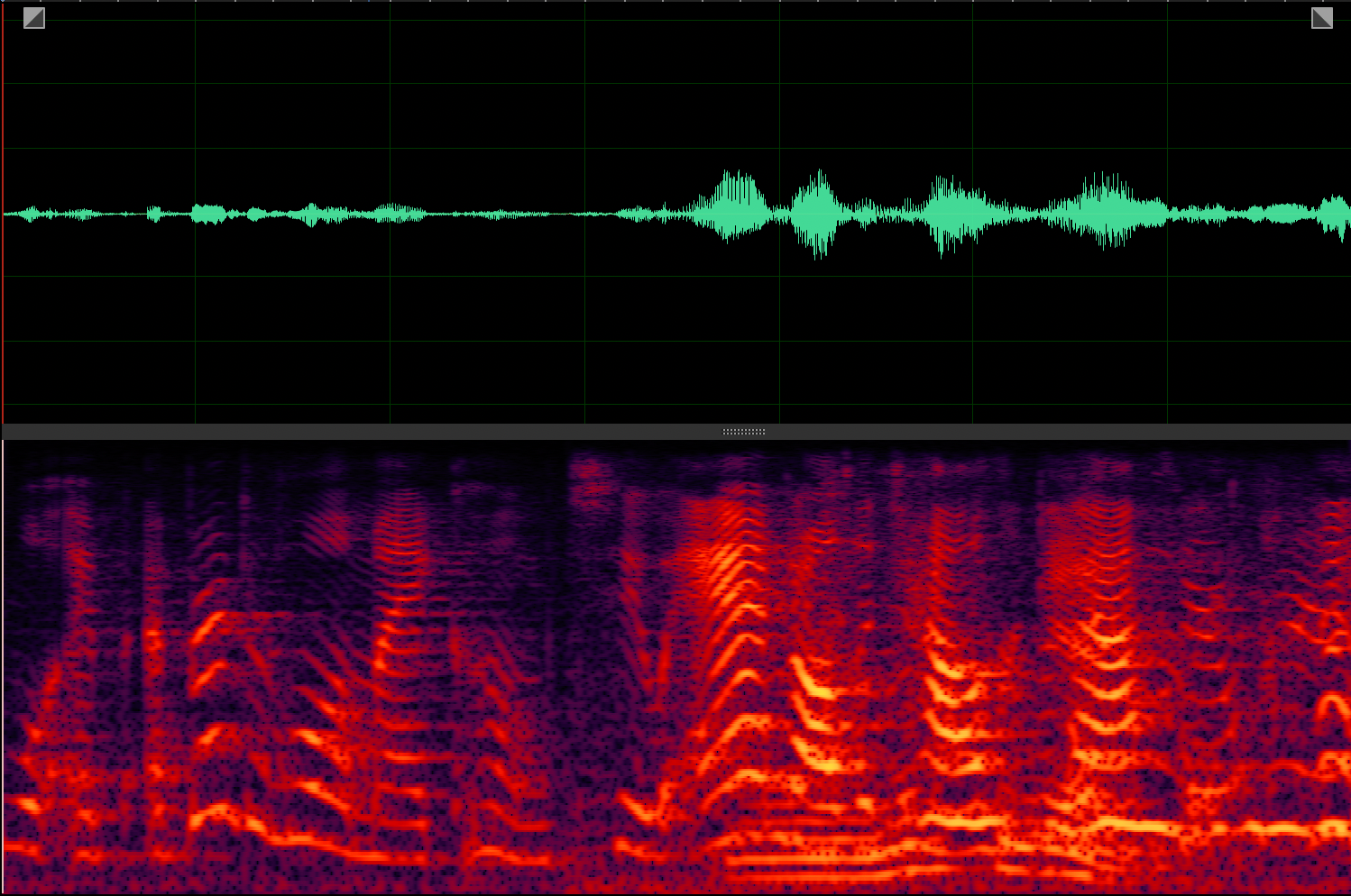
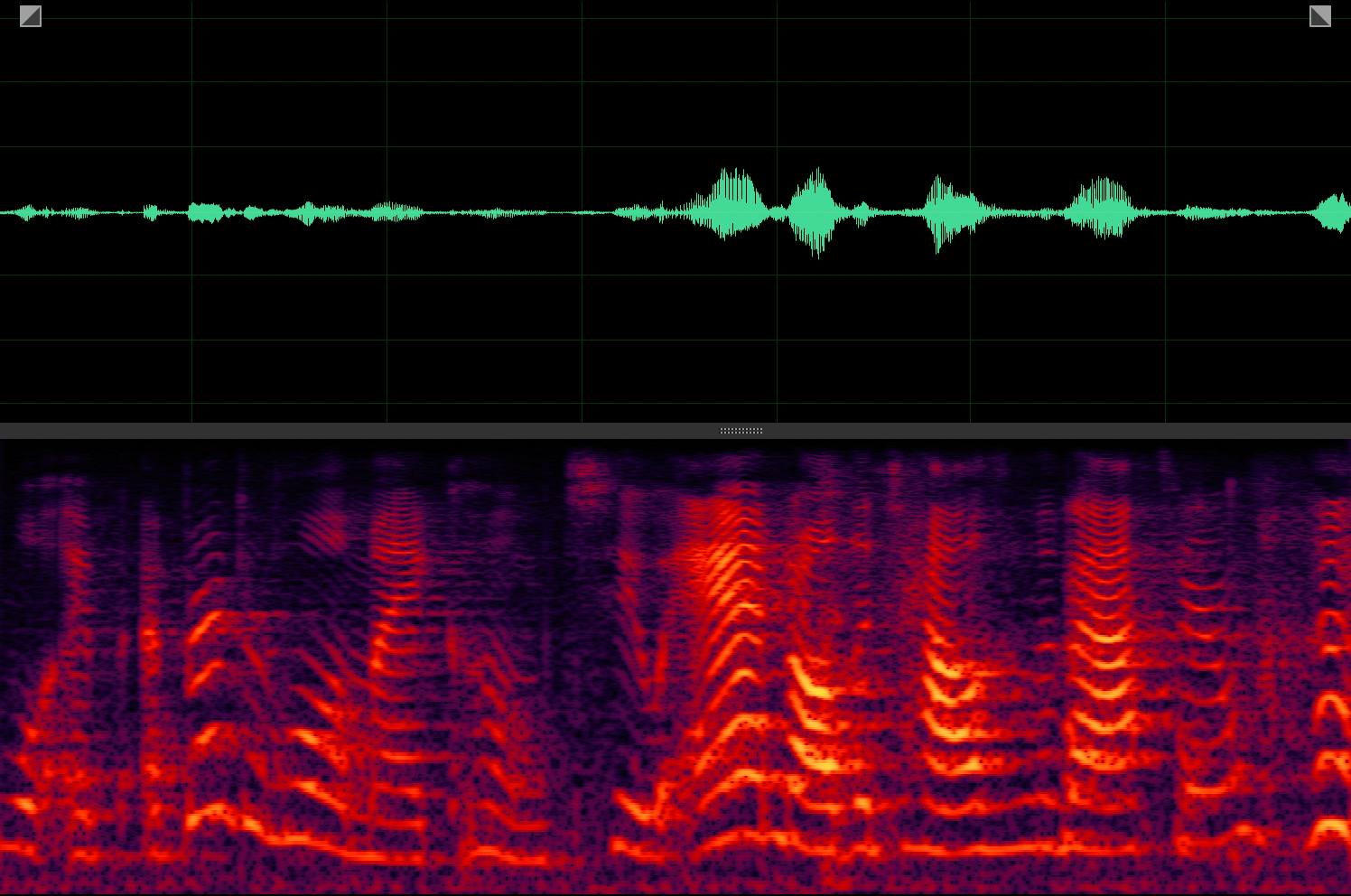
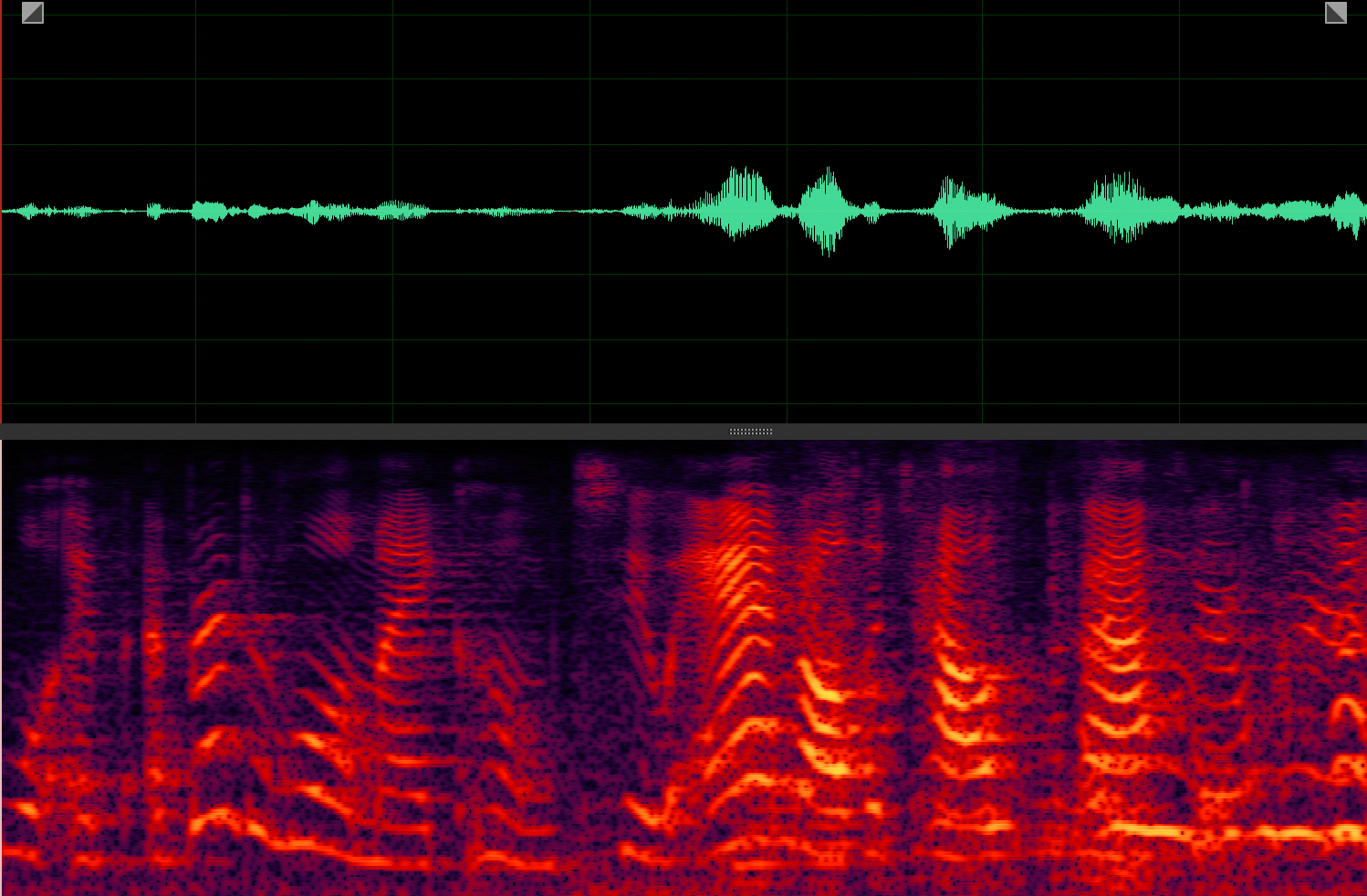
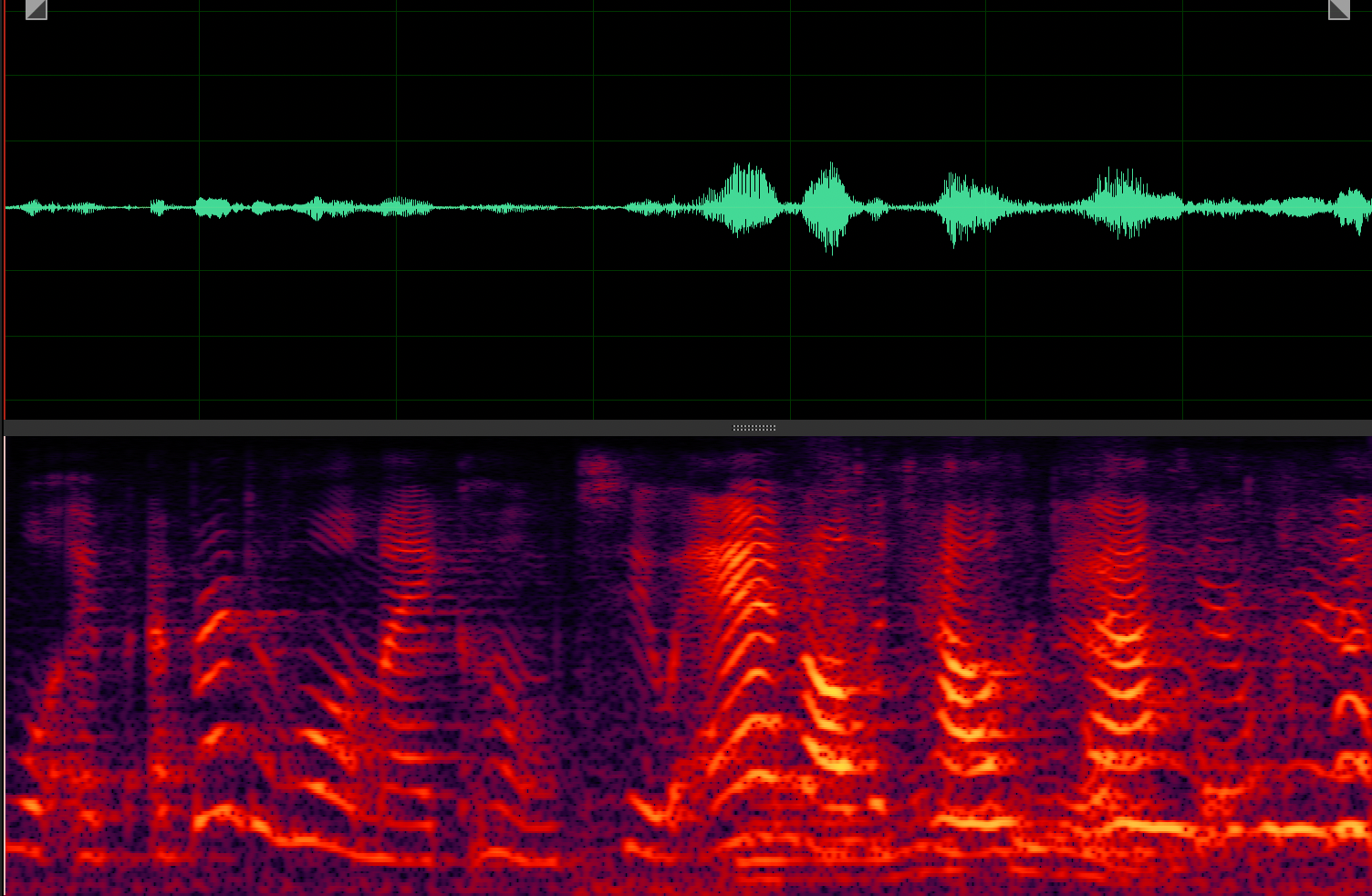
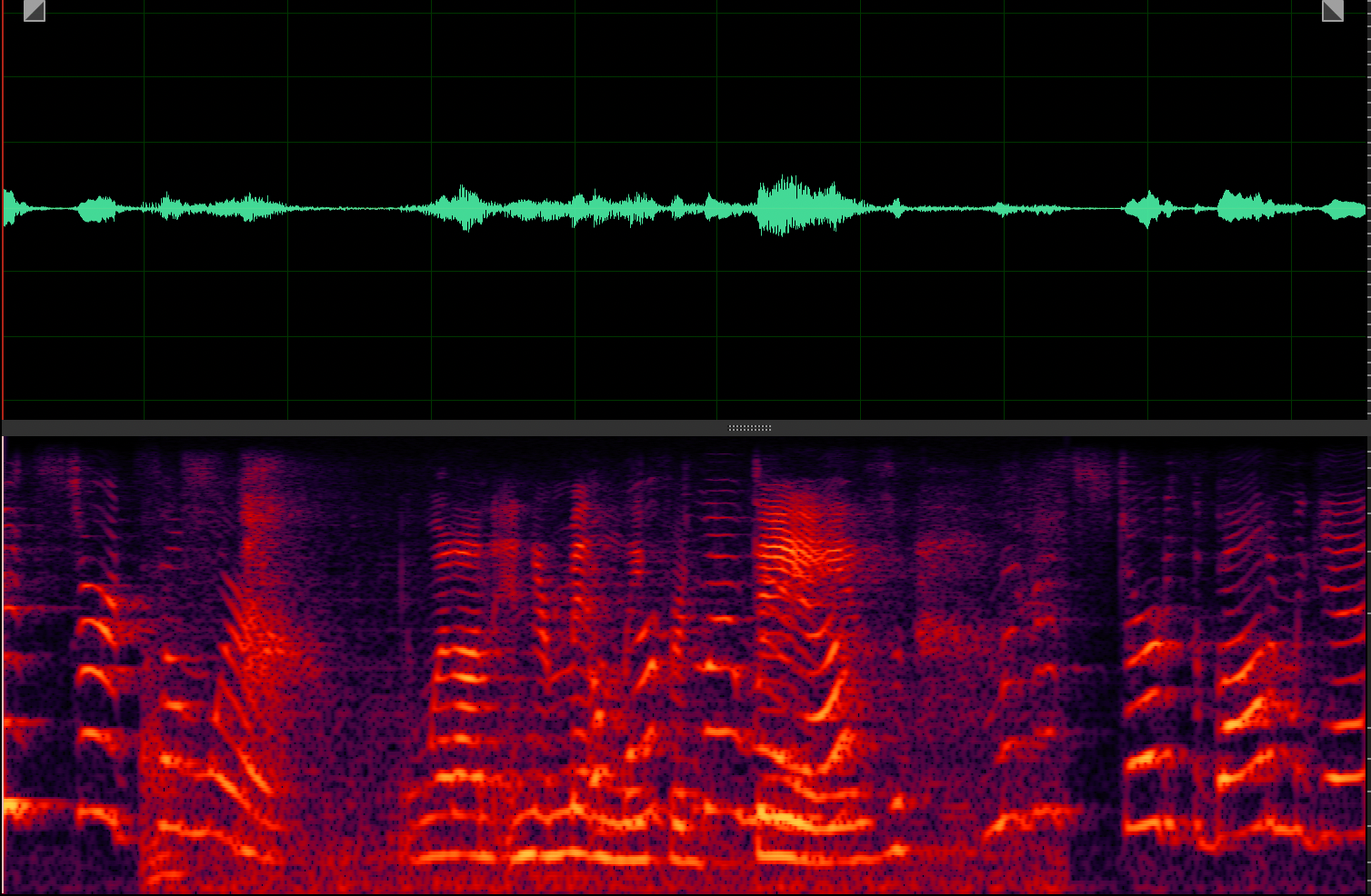
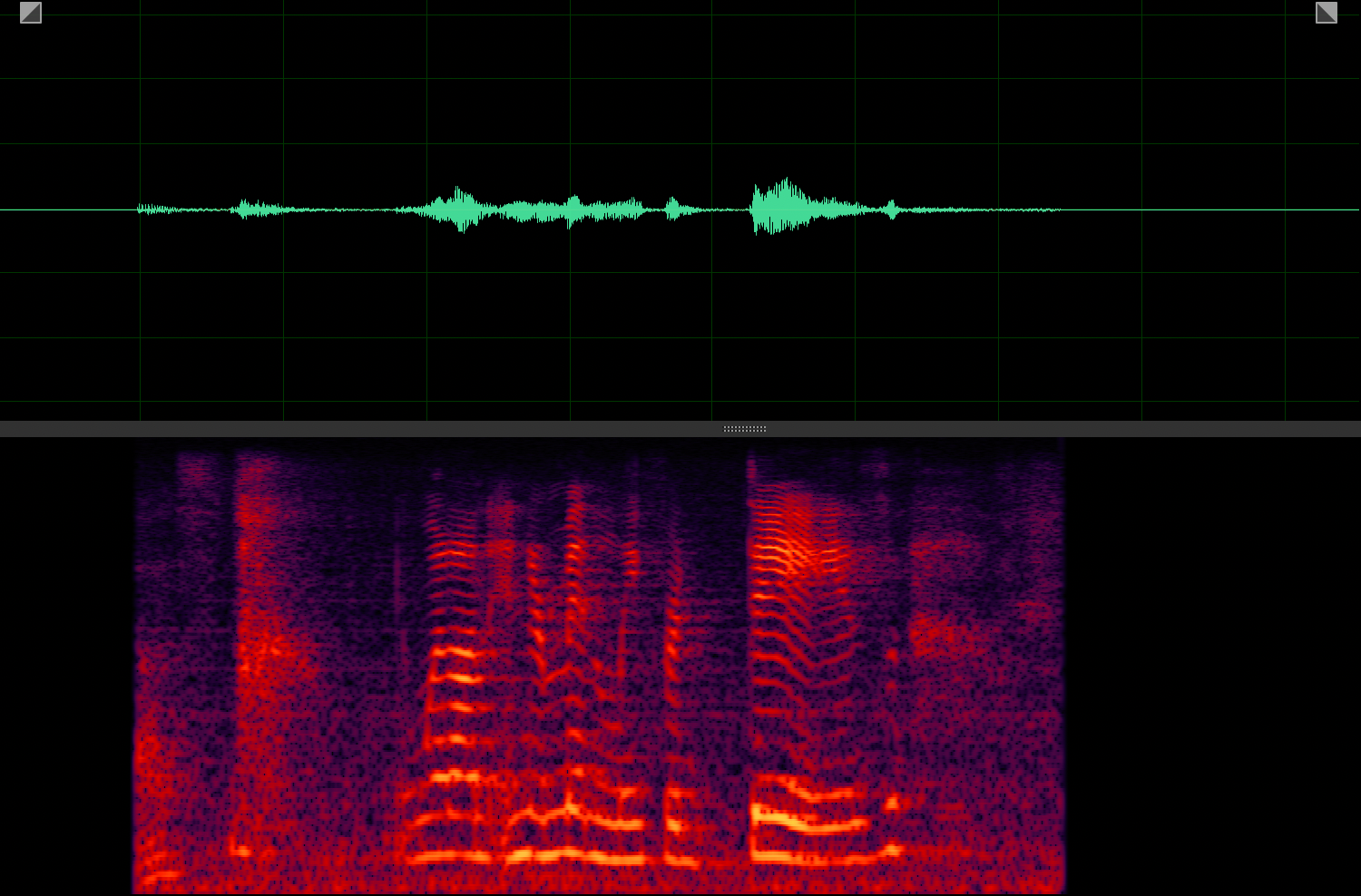
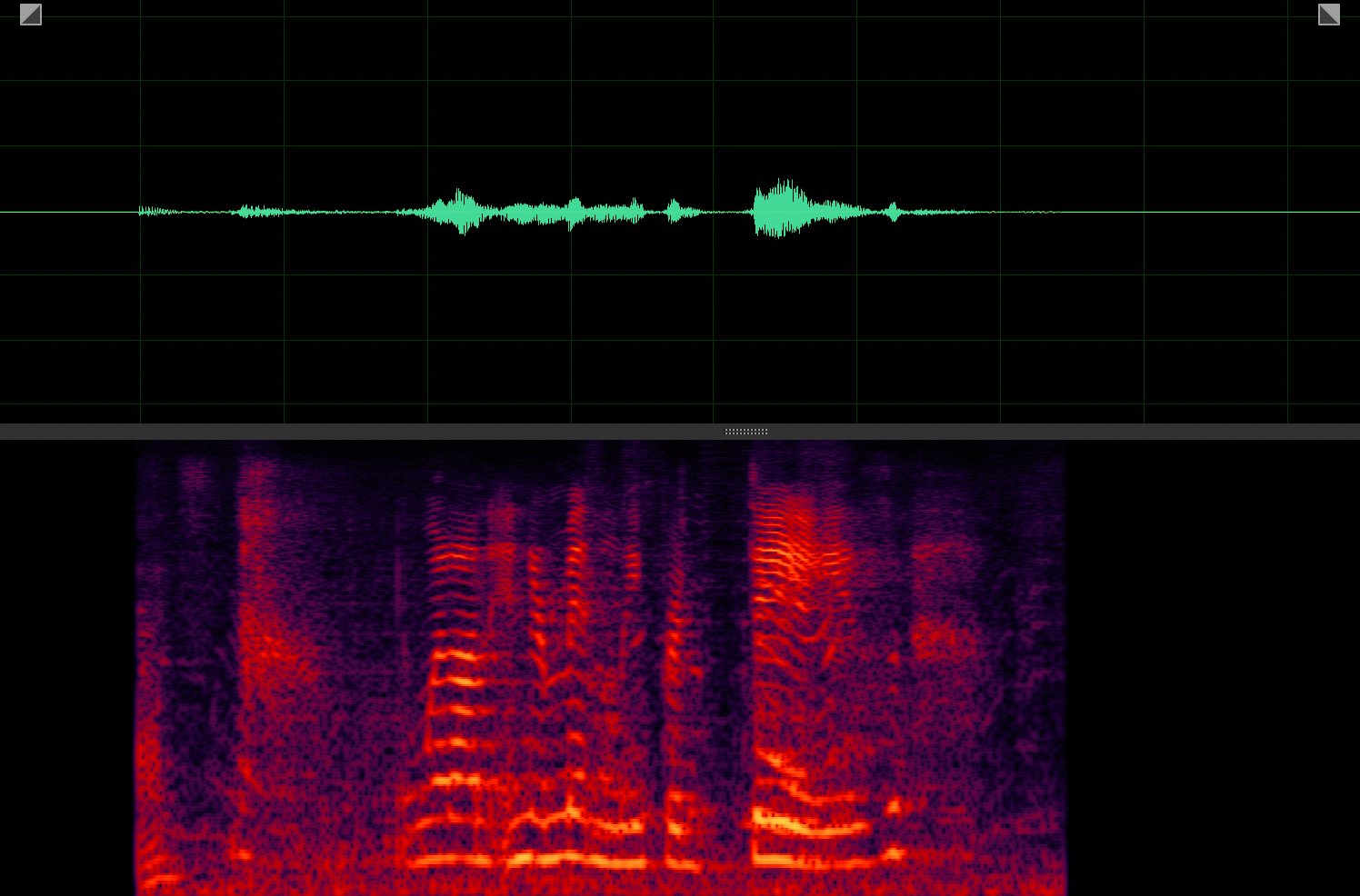
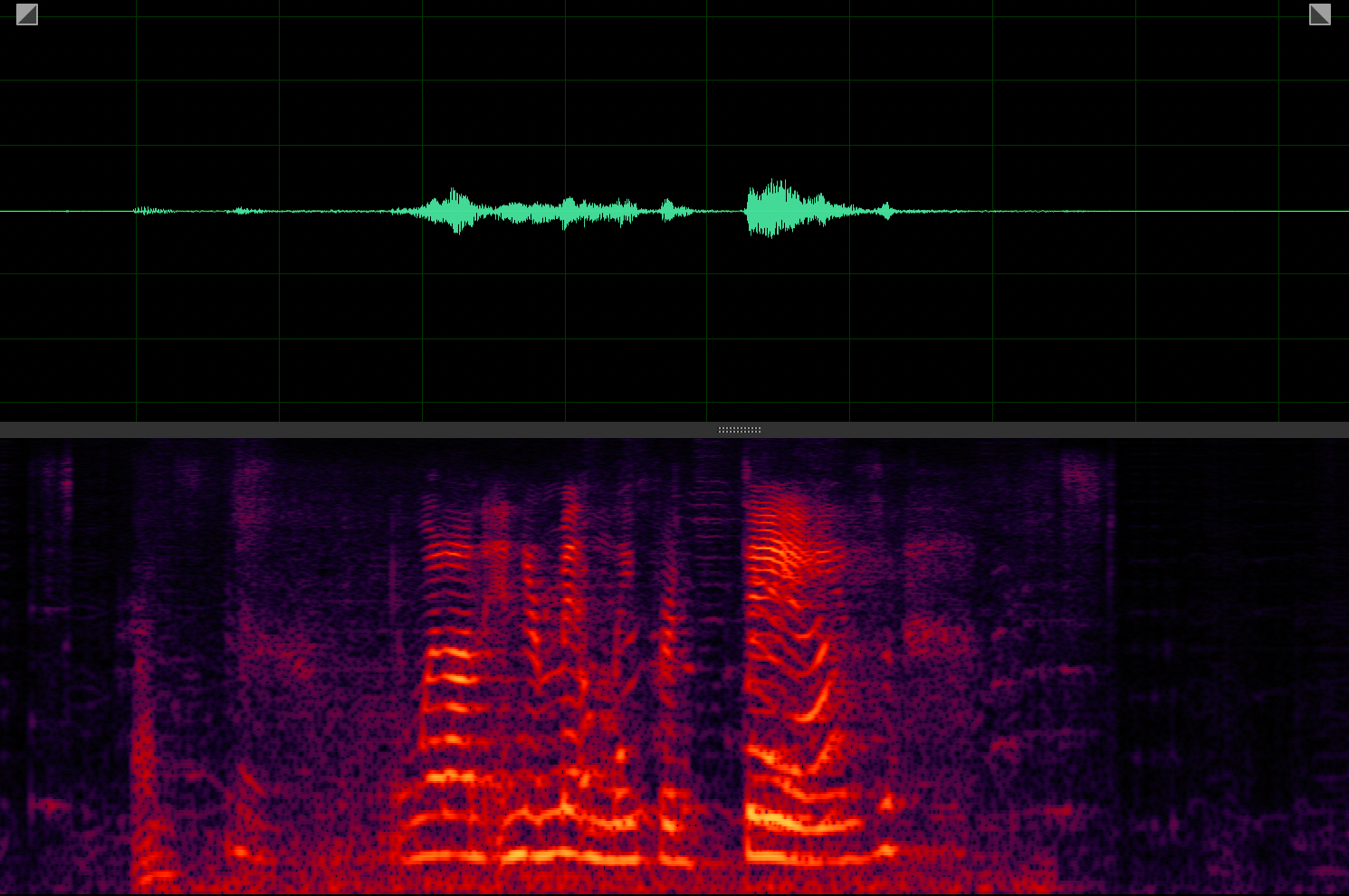
Target speaker extraction aims to extract the speech of a specific speaker from a multi-talker mixture as specified by an auxiliary reference.
Most studies focus on the scenario where the target speech is highly overlapped with the interfering speech.
However, this scenario only accounts for a small percentage of real-world conversations. In this paper,
we aim at the sparsely overlapped scenarios in which the auxiliary reference needs to perform two tasks simultaneously:
detect the activity of the target speaker and disentangle the active speech from any interfering speech.
We propose an audio-visual speaker extraction model named ActiveExtract, which leverages speaking activity from audio-visual active speaker detection (ASD).
The ASD directly provides the frame-level activity of the target speaker, while its intermediate feature representation is trained to discriminate speech-lip
synchronization that could be used for speaker disentanglement. Experimental results show our model outperforms baselines across various overlapping ratios,
achieving an average improvement of more than 4 dB in terms of SI-SNR.
2. Videos
2.1 Real Conversation
In this section, instead of using IEMOCAP-2mix, we train a model using more data to handle real conversation scenarios.
Dataset:
Speech: Voxceleb2, LRS3, Mead and an unreleased dataset CUHK-law
Noise: Musan,NoiseX-92 and wham_noise
Reverberation: SLR26 and SLR28
2.1.1 Fully-overlapped speech
2.1.2 Conversational speech
2.1.3 Single Speaker Speaking
Thanks to Xinyi Chen and Xi Chen for helping me record this video.
3. AudioSamples
In this section, model is pretrained using Voxceleb2-2Mix and finetuned using IEMOCAP-2mix.
Baselines: AV-Sepformer, USEV, ASD+AV-Sepformer
Proposed method: ActiveExtract
3.1 Target Absent Clips
Mixture
Clean
AV-Sepformer[1]
USEV[2]
ASD+AV-Sepformer
ActiveExtract
3.2 0% overlapping ratio
Mixture
Clean
AV-Sepformer[1]
USEV[2]
ASD+AV-Sepformer
ActiveExtract
3.3 (0%,20%] overlapping ratio
Mixture
Clean
AV-Sepformer[1]
USEV[2]
ASD+AV-Sepformer
ActiveExtract
3.4 (20%,40%] overlapping ratio
Mixture
Clean
AV-Sepformer[1]
USEV[2]
ASD+AV-Sepformer
ActiveExtract
3.5 (40%,60%] overlapping ratio
Mixture
Clean
AV-Sepformer[1]
USEV[2]
ASD+AV-Sepformer
ActiveExtract
3.6 (60%,80%] overlapping ratio
Mixture
Clean
AV-Sepformer[1]
USEV[2]
ASD+AV-Sepformer
ActiveExtract
3.7 (80%,100%] overlapping ratio
Mixture
Clean
AV-Sepformer[1]
USEV[2]
ASD+AV-Sepformer
ActiveExtract
[1] Lin, Jiuxin, et al. "AV-Sepformer: Cross-Attention Sepformer for Audio-Visual Target Speaker Extraction." ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023.
[2] Pan, Zexu, Meng Ge, and Haizhou Li. "USEV: Universal speaker extraction with visual cue." IEEE/ACM Transactions on Audio, Speech, and Language Processing 30 (2022): 3032-3045.